开篇
本篇以aosp分支android-11.0.0_r25,kernel分支android-msm-wahoo-4.4-android11作为基础解析
上一篇文章Android源码分析 - Binder概述我们大概了解了一下Android选用Binder的原因,以及Binder的基本结构和通信过程。今天,我们便开始从Binder驱动层代码开始分析Binder的机制
提示
Binder驱动部分代码不在AOSP项目中,所以我们需要单独clone一份驱动代码
由于我的开发设备是pixel2,查了Linux内核版本号为4.4.223,对应的分支为android-msm-wahoo-4.4-android11,所以今天的分析我们也是基于此分支
我是从清华大学镜像站clone的代码,高通的设备,所以地址为:https://aosp.tuna.tsinghua.edu.cn/android/kernel/msm.git
初始化
binder驱动的源码位于drivers/android目录下,我们从binder.c文件看起
Linux initcall机制
在binder.c的最底下,我们可以看到这一行代码
1
| device_initcall(binder_init);
|
在Linux内核中,驱动程序通常是用xxx_initcall(fn)启动的,这实际上是一个宏定义,被定义在平台对应的init.h文件中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| #define early_initcall(fn) __define_initcall(fn, early)
#define pure_initcall(fn) __define_initcall(fn, 0)
#define core_initcall(fn) __define_initcall(fn, 1)
#define core_initcall_sync(fn) __define_initcall(fn, 1s)
#define postcore_initcall(fn) __define_initcall(fn, 2)
#define postcore_initcall_sync(fn) __define_initcall(fn, 2s)
#define arch_initcall(fn) __define_initcall(fn, 3)
#define arch_initcall_sync(fn) __define_initcall(fn, 3s)
#define subsys_initcall(fn) __define_initcall(fn, 4)
#define subsys_initcall_sync(fn) __define_initcall(fn, 4s)
#define fs_initcall(fn) __define_initcall(fn, 5)
#define fs_initcall_sync(fn) __define_initcall(fn, 5s)
#define rootfs_initcall(fn) __define_initcall(fn, rootfs)
#define device_initcall(fn) __define_initcall(fn, 6)
#define device_initcall_sync(fn) __define_initcall(fn, 6s)
#define late_initcall(fn) __define_initcall(fn, 7)
#define late_initcall_sync(fn) __define_initcall(fn, 7s)
|
可以看到,实际上调用的是__define_initcall()函数,这个函数的第二个参数表示优先级,数字越小,优先级越高,带s的优先级低于不带s的优先级
在Linux内核启动过程中,需要调用各种函数,在底层实现是通过在内核镜像文件中,自定义一个段,这个段里面专门用来存放这些初始化函数的地址,内核启动时,只需要在这个段地址处取出函数指针,一个个执行即可,而__define_initcall()函数,就是将自定义的init函数添加到上述段中
binder_init
了解了以上函数定义后,我们再回头看device_initcall(binder_init)就可以知道,在Linux内核启动时,会调用binder_init这么一个函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| static int __init binder_init(void)
{
int ret;
char *device_name, *device_names, *device_tmp;
struct binder_device *device;
struct hlist_node *tmp;
ret = binder_alloc_shrinker_init();
if (ret)
return ret;
...
binder_deferred_workqueue = create_singlethread_workqueue("binder");
if (!binder_deferred_workqueue)
return -ENOMEM;
binder_debugfs_dir_entry_root = debugfs_create_dir("binder", NULL);
if (binder_debugfs_dir_entry_root)
binder_debugfs_dir_entry_proc = debugfs_create_dir("proc",
binder_debugfs_dir_entry_root);
if (binder_debugfs_dir_entry_root) {
debugfs_create_file("state",
0444,
binder_debugfs_dir_entry_root,
NULL,
&binder_state_fops);
debugfs_create_file("stats",
0444,
binder_debugfs_dir_entry_root,
NULL,
&binder_stats_fops);
debugfs_create_file("transactions",
0444,
binder_debugfs_dir_entry_root,
NULL,
&binder_transactions_fops);
debugfs_create_file("transaction_log",
0444,
binder_debugfs_dir_entry_root,
&binder_transaction_log,
&binder_transaction_log_fops);
debugfs_create_file("failed_transaction_log",
0444,
binder_debugfs_dir_entry_root,
&binder_transaction_log_failed,
&binder_transaction_log_fops);
}
device_names = kzalloc(strlen(binder_devices_param) + 1, GFP_KERNEL);
if (!device_names) {
ret = -ENOMEM;
goto err_alloc_device_names_failed;
}
strcpy(device_names, binder_devices_param);
device_tmp = device_names;
while ((device_name = strsep(&device_tmp, ","))) {
ret = init_binder_device(device_name);
if (ret)
goto err_init_binder_device_failed;
}
return ret;
err_init_binder_device_failed:
...
err_alloc_device_names_failed:
...
}
|
我们将重点放在init_binder_device函数上
init_binder_device
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| static int __init init_binder_device(const char *name)
{
int ret;
struct binder_device *binder_device;
binder_device = kzalloc(sizeof(*binder_device), GFP_KERNEL);
if (!binder_device)
return -ENOMEM;
binder_device->miscdev.fops = &binder_fops;
binder_device->miscdev.minor = MISC_DYNAMIC_MINOR;
binder_device->miscdev.name = name;
binder_device->context.binder_context_mgr_uid = INVALID_UID;
binder_device->context.name = name;
mutex_init(&binder_device->context.context_mgr_node_lock);
ret = misc_register(&binder_device->miscdev);
if (ret < 0) {
kfree(binder_device);
return ret;
}
hlist_add_head(&binder_device->hlist, &binder_devices);
return ret;
}
|
先构造了一个结构体用来存放binder参数,然后通过misc_register函数,以misc设备进行注册binder,作为虚拟字符设备
注册misc设备
我们先学习一下在Linux中如何注册一个misc设备
在Linux驱动中把无法归类的五花八门的设备定义为misc设备,Linux内核所提供的misc设备有很强的包容性,各种无法归结为标准字符设备的类型都可以定义为misc设备,譬如NVRAM,看门狗,实时时钟,字符LCD等
在Linux内核里把所有的misc设备组织在一起,构成了一个子系统(subsys),统一进行管理。在这个子系统里的所有miscdevice类型的设备共享一个主设备号MISC_MAJOR(10),但次设备号不同
在内核中用miscdevice结构体表示misc设备,具体的定义在include/linux/miscdevice.h中
1
2
3
4
5
6
7
8
9
10
11
| struct miscdevice {
int minor;
const char *name;
const struct file_operations *fops;
struct list_head list;
struct device *parent;
struct device *this_device;
const struct attribute_group **groups;
const char *nodename;
umode_t mode;
};
|
我们自己注册misc设备时只需要填入前3项即可:
minor:次设备号,如果填充MISC_DYNAMIC_MINOR,则由内核动态分配次设备号name:设备名fops:file_operations结构体,用于定义自己misc设备的文件操作函数,如果不填此项则会使用默认的misc_fops
file_operations结构体被定义在include/linux/fs.h中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iterate) (struct file *, struct dir_context *);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **, void **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
void (*show_fdinfo)(struct seq_file *m, struct file *f);
#ifndef CONFIG_MMU
unsigned (*mmap_capabilities)(struct file *);
#endif
};
|
file_operation是把系统调用和驱动程序关联起来的关键结构,这个结构的每一个成员都对应着一个系统调用,Linux系统调用通过读取file_operation中相应的函数指针,接着把控制权转交给函数,从而完成Linux设备驱动程序的工作
最后调用misc_register函数注册misc设备,函数原型如下:
1
2
3
4
|
extern int misc_register(struct miscdevice *misc);
extern void misc_deregister(struct miscdevice *misc);
|
注册binder设备
了解了misc设备的注册,我们就可以看一下binder的注册过程了,代码中先构建了一个binder_device结构体,我们先观察一下这个结构体长什么样子
1
2
3
4
5
| struct binder_device {
struct hlist_node hlist;
struct miscdevice miscdev;
struct binder_context context;
};
|
其中的hlist_node是链表中的一个节点,miscdevice就是上文所描述的注册misc所必要的结构体参数,binder_context用于保存binder上下文管理者的信息
回到代码中,首先给miscdevice赋了值,指定了file_operation,设置了minor动态分配次设备号,binder_context则是简单初始化了一下,然后便调用misc_register函数注册misc设备,最后将这个binder设备使用头插法加入到一个全局链表中
我们看一下它指定的file_operation
1
2
3
4
5
6
7
8
9
10
| static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
|
可以看到,binder驱动支持以上7种系统调用,接下来,我们就逐一分析这些系统调用
binder_proc
在分析这些系统调用前,我们有必要先了解一下在binder中非常重要的结构体binder_proc,它是用来描述进程上下文信息以及管理IPC的一个结构体,被定义在drivers/android/binder.c中,是一个私有的结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| struct binder_proc {
struct hlist_node proc_node;
struct rb_root threads;
struct rb_root nodes;
struct rb_root refs_by_desc;
struct rb_root refs_by_node;
struct list_head waiting_threads;
int pid;
struct task_struct *tsk;
struct files_struct *files;
struct mutex files_lock;
struct hlist_node deferred_work_node;
int deferred_work;
bool is_dead;
struct list_head todo;
struct binder_stats stats;
struct list_head delivered_death;
int max_threads;
int requested_threads;
int requested_threads_started;
atomic_t tmp_ref;
struct binder_priority default_priority;
struct dentry *debugfs_entry;
struct binder_alloc alloc;
struct binder_context *context;
spinlock_t inner_lock;
spinlock_t outer_lock;
};
|
binder_open
我们先从打开binder驱动设备开始
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
struct binder_device *binder_dev;
...
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
spin_lock_init(&proc->inner_lock);
spin_lock_init(&proc->outer_lock);
atomic_set(&proc->tmp_ref, 0);
get_task_struct(current->group_leader);
proc->tsk = current->group_leader;
mutex_init(&proc->files_lock);
INIT_LIST_HEAD(&proc->todo);
if (binder_supported_policy(current->policy)) {
proc->default_priority.sched_policy = current->policy;
proc->default_priority.prio = current->normal_prio;
} else {
proc->default_priority.sched_policy = SCHED_NORMAL;
proc->default_priority.prio = NICE_TO_PRIO(0);
}
binder_dev = container_of(filp->private_data, struct binder_device,
miscdev);
proc->context = &binder_dev->context;
binder_alloc_init(&proc->alloc);
binder_stats_created(BINDER_STAT_PROC);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
INIT_LIST_HEAD(&proc->waiting_threads);
filp->private_data = proc;
mutex_lock(&binder_procs_lock);
hlist_add_head(&proc->proc_node, &binder_procs);
mutex_unlock(&binder_procs_lock);
if (binder_debugfs_dir_entry_proc) {
char strbuf[11];
snprintf(strbuf, sizeof(strbuf), "%u", proc->pid);
proc->debugfs_entry = debugfs_create_file(strbuf, 0444,
binder_debugfs_dir_entry_proc,
(void *)(unsigned long)proc->pid,
&binder_proc_fops);
}
return 0;
}
|
binder_open函数创建了binder_proc结构体,并把初始化并将当前进程等信息保存到binder_proc结构体中,然后将binder_proc结构体保存到文件指针filp的private_data中,再将binder_proc加入到全局链表binder_procs中
这里面有一些关于Linux的知识需要解释一下
spinlock
spinlock是内核中提供的一种自旋锁机制。在Linux内核实现中,常常会碰到共享数据被中断上下文和进程上下文访问的场景,如果只有进程上下文的话,我们可以使用互斥锁或者信号量解决,将未获得锁的进程置为睡眠状态等待,但由于中断上下文不是一个进程,它不存在task_struct,所以不可被调度,当然也就不可睡眠,这时候就可以通过spinlock自旋锁的忙等待机制来达成睡眠同样的效果
current
在Linux内核中,定义了一个叫current的宏,它被定义在asm/current.h中
1
2
3
4
5
6
| static inline struct task_struct *get_current(void)
{
return(current_thread_info()->task);
}
#define current get_current()
|
它返回一个task_struct指针,指向执行当前这段内核代码的进程
container_of
container_of也是Linux中定义的一个宏,它的作用是根据一个结构体变量中的一个域成员变量的指针来获取指向整个结构体变量的指针
1
2
3
4
5
| #define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
|
fd&filp
filp->private_data保存了binder_proc结构体,当进程调用open系统函数时,内核会返回一个文件描述符fd,这个fd指向文件指针filp,在后续调用mmap,ioctl等函数与binder驱动交互时,会传入这个fd,内核就会以这个fd指向文件指针filp作为参数调用binder_mmap,binder_ioctl等函数,这样这些函数就可以通过filp->private_data取出binder_proc结构体
binder_mmap
vm_area_struct
在分析mmap前,我们需要先了解一下vm_area_struct这个结构体,它被定义在include/linux/mm_types.h中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| struct vm_area_struct {
unsigned long vm_start;
unsigned long vm_end;
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
unsigned long rb_subtree_gap;
struct mm_struct *vm_mm;
pgprot_t vm_page_prot;
unsigned long vm_flags;
union {
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
const char __user *anon_name;
};
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops;
unsigned long vm_pgoff;
struct file * vm_file;
void * vm_private_data;
#ifndef CONFIG_MMU
struct vm_region *vm_region;
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy;
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
};
|
vm_area_struct结构体描述了一段虚拟内存空间,通常,进程所使用到的虚拟内存空间不连续,且各部分虚存空间的访问属性也可能不同,所以一个进程的虚拟内存空间需要多个vm_area_struct结构来描述(后面简称vma)
每个进程都有一个对应的task_struct结构描述,这个task_struct结构中有一个mm_struct结构用于描述进程的内存空间,mm_struct结构中有两个域成员变量分别指向了vma链表头和红黑树根
vma所描述的虚拟内存空间范围由vm_start和vm_end表示,vm_start代表当前vma的首地址,vm_end代表当前vma的末地址后第一个字节的地址,即虚拟内存空间范围为[vm_start, vm_end)
vm_operations_struct和上文中的file_operations类似,用来定义虚拟内存的操作函数
介绍完vma,接下来我们便看一下binder_mmap函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
if (proc->tsk != current->group_leader)
return -EINVAL;
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
...
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
vma->vm_flags |= VM_DONTCOPY | VM_MIXEDMAP;
vma->vm_flags &= ~VM_MAYWRITE;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
ret = binder_alloc_mmap_handler(&proc->alloc, vma);
if (ret)
return ret;
mutex_lock(&proc->files_lock);
proc->files = get_files_struct(current);
mutex_unlock(&proc->files_lock);
return 0;
err_bad_arg:
pr_err("%s: %d %lx-%lx %s failed %d\n", __func__,
proc->pid, vma->vm_start, vma->vm_end, failure_string, ret);
return ret;
}
|
- 首先从
filp中获取对应的binder_proc信息
- 将它的进程
task_struct和执行当前这段内核代码的进程task_struct对比校验
- 限制了用户空间虚拟内存的大小在4M以内
- 检查用户空间是否可写(
binder驱动为进程分配的缓冲区在用户空间中只可以读,不可以写)
- 设置
vm_flags,令vma不可写,不可复制
- 设置
vma的操作函数集
- 将
vm_area_struct中的成员变量vm_private_data指向binder_proc,使得vma设置的操作函数中可以拿到binder_proc
- 处理进程虚拟内存空间与内核虚拟地址空间的映射关系
- 获取进程的打开文件信息结构体
files_struct,令binder_proc的files指向它,并将引用计数加1
binder_alloc_mmap_handler
binder_alloc_mmap_handler将进程虚拟内存空间与内核虚拟地址空间做映射,它被实现在drivers/android/binder_alloc.c中
这里先介绍一下vm_struct,之前我们已经了解了vm_area_struct表示用户进程中的虚拟地址空间,而相对应的,vm_struct则表示内核中的虚拟地址空间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| int binder_alloc_mmap_handler(struct binder_alloc *alloc,
struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
const char *failure_string;
struct binder_buffer *buffer;
mutex_lock(&binder_alloc_mmap_lock);
if (alloc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
area = get_vm_area(vma->vm_end - vma->vm_start, VM_ALLOC);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
alloc->buffer = area->addr;
alloc->user_buffer_offset =
vma->vm_start - (uintptr_t)alloc->buffer;
mutex_unlock(&binder_alloc_mmap_lock);
...
alloc->pages = kzalloc(sizeof(alloc->pages[0]) *
((vma->vm_end - vma->vm_start) / PAGE_SIZE),
GFP_KERNEL);
if (alloc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
alloc->buffer_size = vma->vm_end - vma->vm_start;
buffer = kzalloc(sizeof(*buffer), GFP_KERNEL);
if (!buffer) {
ret = -ENOMEM;
failure_string = "alloc buffer struct";
goto err_alloc_buf_struct_failed;
}
buffer->data = alloc->buffer;
list_add(&buffer->entry, &alloc->buffers);
buffer->free = 1;
binder_insert_free_buffer(alloc, buffer);
alloc->free_async_space = alloc->buffer_size / 2;
barrier();
alloc->vma = vma;
alloc->vma_vm_mm = vma->vm_mm;
atomic_inc(&alloc->vma_vm_mm->mm_count);
return 0;
...
}
|
- 检查是否已经分配过内核缓冲区
- 从内核中寻找一块可用的虚拟内存地址
- 将此内核虚拟内存空间地址保存至
binder_alloc
- 计算出用户虚拟空间线性地址到内核虚拟空间线性地址的偏移量(这样就可以非常方便的在用户虚拟内存空间与内核虚拟内存空间间切换)
- 为
alloc->pages数组申请内存,申请的大小等于vma能分配多少个页框
- 设置
buffer大小等于vma大小
- 为
binder_buffer申请内存,填充参数,使其指向内核虚拟空间地址,并将其添加到链表和红黑树中
- 设置
binder_alloc其他参数
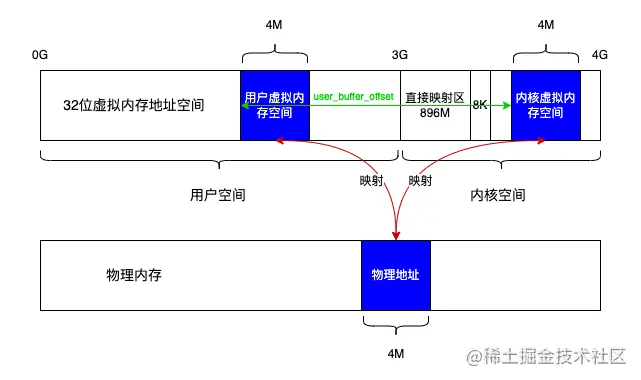
这里要注意,虽然我们计算出了用户虚拟空间线性地址到内核虚拟空间线性地址的偏移量,但并没有建立映射关系。在旧版内核中,这里会调用binder_update_page_range函数分别将内核虚拟内存和进程虚拟内存与物理内存做映射,这样内核虚拟内存和进程虚拟内存也相当于间接建立了映射关系,而在4.4.223中,这件事将会延迟到binder_ioctl后
当完成物理内存的映射后,以32位系统,缓冲区大小4M为例,效果应该如下图所示:
总结
到这里,我们已经了解了binder驱动设备是如何注册的,并且分析了binder_open和binder_mmap操作函数,了解了一些重要的结构体,明白了mmap是如何映射用户空间和内核空间的,由于篇幅原因,下一章我们会分析binder驱动中最重要的部分binder_ioctl
参考文献