开篇 本篇以aosp分支android-11.0.0_r25作为基础解析
我们在之前的文章中,从驱动层面分析了Binder是怎样工作的,但Binder驱动只涉及传输部分,待传输对象是怎么产生的呢,这就是framework层的工作了。我们要彻底了解Binder的工作原理,不仅要去看驱动层,还得去看framework层以及应用层(AIDL)
ServiceManager getIServiceManager 我们还是以第一次见到Binder的地方ServiceManager开始分析,我们选取getService方法来分析(这个方法既有入参也有返回),抛除掉它缓存和log的部分,最核心的代码就一句getIServiceManager().getService(name)
1 2 3 4 5 6 7 8 9 10 private static IServiceManager getIServiceManager () if (sServiceManager != null ) { return sServiceManager; } sServiceManager = ServiceManagerNative .asInterface(Binder.allowBlocking(BinderInternal.getContextObject())); return sServiceManager; }
BinderInternal.getContextObject 我们从BinderInternal.getContextObject()开始看起,这个函数是一个native函数,他被实现在frameworks/base/core/jni/android_util_Binder.cpp中
1 2 3 4 5 static jobject android_os_BinderInternal_getContextObject (JNIEnv* env, jobject clazz) sp<IBinder> b = ProcessState::self()->getContextObject(NULL ); return javaObjectForIBinder(env, b); }
ProcessState 我们在这里可以发现一个比较关键的类ProcessState,它是一个负责打开binder驱动并进行mmap映射的单例对象,这从它的self函数就可以看出来,每个进程只存在一个ProcessState实例
位置:frameworks/native/libs/binder/ProcessState.cpp
1 2 3 4 5 6 7 8 9 sp<ProcessState> ProcessState::self () Mutex::Autolock _l(gProcessMutex); if (gProcess != nullptr ) { return gProcess; } gProcess = new ProcessState(kDefaultDriver); return gProcess; }
我们来看看它的构造函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ProcessState::ProcessState(const char *driver) : mDriverName(String8(driver)) , mDriverFD(open_driver(driver)) , mVMStart(MAP_FAILED) , mThreadCountLock(PTHREAD_MUTEX_INITIALIZER) , mThreadCountDecrement(PTHREAD_COND_INITIALIZER) , mExecutingThreadsCount(0 ) , mMaxThreads(DEFAULT_MAX_BINDER_THREADS) , mStarvationStartTimeMs(0 ) , mBinderContextCheckFunc(nullptr ) , mBinderContextUserData(nullptr ) , mThreadPoolStarted(false ) , mThreadPoolSeq(1 ) , mCallRestriction(CallRestriction::NONE) { if (mDriverFD >= 0 ) { mVMStart = mmap(nullptr , BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0 ); ... } }
这里的:后是c++构造函数初始化赋值的一种语法,可以看到其中调用了open_driver函数打开binder驱动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static int open_driver (const char *driver) int fd = open(driver, O_RDWR | O_CLOEXEC); int vers = 0 ; status_t result = ioctl(fd, BINDER_VERSION, &vers); if (result != 0 || vers != BINDER_CURRENT_PROTOCOL_VERSION) { ... } size_t maxThreads = DEFAULT_MAX_BINDER_THREADS; result = ioctl(fd, BINDER_SET_MAX_THREADS, &maxThreads); return fd; }
这里做了三件事,打开binder驱动、验证binder版本、设置binder最大线程数,接着构造函数调用mmap建立binder映射,这里面的实现我们已经在Android源码分析 - Binder驱动(上) 、(中) 、(下) 中分析过了,感兴趣的同学可以回过头去看一看
ProcessState::self函数执行完后,当前进程的binder初始化工作已经执行完毕,接下来我们回过头来看它的getContextObject函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 sp<IBinder> ProcessState::getContextObject (const sp<IBinder>& ) sp<IBinder> context = getStrongProxyForHandle(0 ); if (context == nullptr ) { ALOGW("Not able to get context object on %s." , mDriverName.c_str()); } internal::Stability::tryMarkCompilationUnit(context.get()); return context; }
我们在binder驱动篇就提到了,handle句柄0代表的就是ServiceManager,所以这里调用getStrongProxyForHandle函数的参数为0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 sp<IBinder> ProcessState::getStrongProxyForHandle (int32_t handle) sp<IBinder> result; AutoMutex _l(mLock); handle_entry* e = lookupHandleLocked(handle); if (e != nullptr ) { IBinder* b = e->binder; if (b == nullptr || !e->refs->attemptIncWeak(this )) { if (handle == 0 ) { Parcel data; status_t status = IPCThreadState::self()->transact( 0 , IBinder::PING_TRANSACTION, data, nullptr , 0 ); if (status == DEAD_OBJECT) return nullptr ; } b = BpBinder::create(handle); e->binder = b; if (b) e->refs = b->getWeakRefs(); result = b; } else { result.force_set(b); e->refs->decWeak(this ); } } return result; }
1 2 3 4 5 6 7 8 9 10 11 12 13 ProcessState::handle_entry* ProcessState::lookupHandleLocked (int32_t handle) const size_t N=mHandleToObject.size(); if (N <= (size_t )handle) { handle_entry e; e.binder = nullptr ; e.refs = nullptr ; status_t err = mHandleToObject.insertAt(e, N, handle+1 -N); if (err < NO_ERROR) return nullptr ; } return &mHandleToObject.editItemAt(handle); }
整条链路下来还是比较清晰的,最终获得了一个BpBinder对象,这是native中的类型,需要将它转换成java中的类型,这里调用了javaObjectForIBinder函数,位于frameworks/base/core/jni/android_util_Binder.cpp中
javaObjectForIBinder 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 jobject javaObjectForIBinder (JNIEnv* env, const sp<IBinder>& val) if (val == NULL ) return NULL ; if (val->checkSubclass(&gBinderOffsets)) { jobject object = static_cast <JavaBBinder*>(val.get())->object(); return object; } BinderProxyNativeData* nativeData = new BinderProxyNativeData(); nativeData->mOrgue = new DeathRecipientList; nativeData->mObject = val; jobject object = env->CallStaticObjectMethod(gBinderProxyOffsets.mClass, gBinderProxyOffsets.mGetInstance, (jlong) nativeData, (jlong) val.get()); if (env->ExceptionCheck()) { return NULL ; } BinderProxyNativeData* actualNativeData = getBPNativeData(env, object); if (actualNativeData == nativeData) { ... } else { delete nativeData; } return object; }
我们先看一看这个gBinderProxyOffsets是什么
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 static struct binderproxy_offsets_t { jclass mClass; jmethodID mGetInstance; jmethodID mSendDeathNotice; jfieldID mNativeData; } gBinderProxyOffsets; const char * const kBinderProxyPathName = "android/os/BinderProxy" ;static int int_register_android_os_BinderProxy (JNIEnv* env) ... jclass clazz = FindClassOrDie(env, kBinderProxyPathName); gBinderProxyOffsets.mClass = MakeGlobalRefOrDie(env, clazz); gBinderProxyOffsets.mGetInstance = GetStaticMethodIDOrDie(env, clazz, "getInstance" , "(JJ)Landroid/os/BinderProxy;" ); gBinderProxyOffsets.mSendDeathNotice = GetStaticMethodIDOrDie(env, clazz, "sendDeathNotice" , "(Landroid/os/IBinder$DeathRecipient;Landroid/os/IBinder;)V" ); gBinderProxyOffsets.mNativeData = GetFieldIDOrDie(env, clazz, "mNativeData" , "J" ); ... }
可以看到,gBinderProxyOffsets实际上是一个用来记录一些java中对应类、方法以及字段的结构体,用于从native层调用java层代码
接下来我们看javaObjectForIBinder函数的具体内容
1 2 3 4 5 6 7 8 9 10 11 12 jobject javaObjectForIBinder (JNIEnv* env, const sp<IBinder>& val) if (val == NULL ) return NULL ; if (val->checkSubclass(&gBinderOffsets)) { jobject object = static_cast <JavaBBinder*>(val.get())->object(); return object; } ... }
首先有一个IBinder类型检查的判断,我看了一圈发现目前只有当IBinder的实际类型为JavaBBinder的时候会返回true,其他子类均返回false。JavaBBinder类继承自BBinder,里面保存了对java层Binder对象的引用,所以在这种情况下,直接返回里面的object就好了。
从这里可以看出,native层的javaBBinder与java层的Binder是对应关系
我们这里传进来的是BpBinder,会接着往下走
1 2 3 4 5 6 7 8 9 10 11 jobject javaObjectForIBinder (JNIEnv* env, const sp<IBinder>& val) ... BinderProxyNativeData* nativeData = new BinderProxyNativeData(); nativeData->mOrgue = new DeathRecipientList; nativeData->mObject = val; jobject object = env->CallStaticObjectMethod(gBinderProxyOffsets.mClass, gBinderProxyOffsets.mGetInstance, (jlong) nativeData, (jlong) val.get()); ... }
接着实例化一个BinderProxyNativeData,将Binder死亡回调DeathRecipientList和Binder对象(这里为BpBinder)赋值给它,然后调用java层方法。gBinderProxyOffsets之前说过了,类为android.os.BinderProxy,方法为getInstance,所以这里调用的即为android.os.BinderProxy.getInstance(nativeData, iBinder),BinderProxy的路径为frameworks/base/core/java/android/os/BinderProxy.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private static BinderProxy getInstance (long nativeData, long iBinder) BinderProxy result; synchronized (sProxyMap) { try { result = sProxyMap.get(iBinder); if (result != null ) { return result; } result = new BinderProxy(nativeData); } catch (Throwable e) { NativeAllocationRegistry.applyFreeFunction(NoImagePreloadHolder.sNativeFinalizer, nativeData); throw e; } NoImagePreloadHolder.sRegistry.registerNativeAllocation(result, nativeData); sProxyMap.set(iBinder, result); } return result; }
这里的逻辑比较简单,以iBinder为 key 尝试从sProxyMap取出BinderProxy,如果取到值了就直接将它返回出去,如果没取到,用之前传进来的BinderProxyNativeData指针为参数实例化一个BinderProxy,并将其设置到sProxyMap中
从这里可以看出每一个服务的BinderProxy都是以单例形式存在的,并且native层的BinderProxyNativeData与java层的BinderProxy是对应关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 BinderProxyNativeData* getBPNativeData (JNIEnv* env, jobject obj) { return (BinderProxyNativeData *) env->GetLongField(obj, gBinderProxyOffsets.mNativeData); } jobject javaObjectForIBinder (JNIEnv* env, const sp<IBinder>& val) ... BinderProxyNativeData* actualNativeData = getBPNativeData(env, object); if (actualNativeData == nativeData) { ... } else { delete nativeData; } return object; }
接下来判断我们通过BinderProxy.getInstance方法获得的BinderProxy是不是刚刚创建出来的,如果是新建的则需要处理一下proxy计数,这里是通过对比BinderProxy中的mNativeData和我们新建出来的nativeData地址判断的
ServiceManagerNative.asInterface 我们将目光放回getIServiceManager方法,现在我们知道BinderInternal.getContextObject()方法返回了ServiceManager对应的BinderProxy,接着会调用Binder.allowBlocking方法,这个方法只是改变了BinderProxy中的一个参数,使其允许阻塞调用,这样的话getIServiceManager就可以被简化成如下代码
1 2 3 4 5 6 7 8 9 10 private static IServiceManager getIServiceManager () if (sServiceManager != null ) { return sServiceManager; } sServiceManager = ServiceManagerNative .asInterface(); return sServiceManager; }
我们看到asInterface方法实际上是直接实例化了一个ServiceManagerProxy对象
1 2 3 4 5 6 7 8 public static IServiceManager asInterface (IBinder obj) if (obj == null ) { return null ; } return new ServiceManagerProxy(obj); }
ServiceManagerProxy 从名字就能听出来,ServiceManagerProxy其实是一个代理类,它其实是IServiceManager.Stub.Proxy的代理,实际上是没有什么必要的,可以发现作者也在注释中标注了This class should be deleted and replaced with IServiceManager.Stub whenever mRemote is no longer used,我们看一下它的构造方法
1 2 3 4 public ServiceManagerProxy (IBinder remote) mRemote = remote; mServiceManager = IServiceManager.Stub.asInterface(remote); }
ServiceManagerProxy实现了IServiceManager接口,但这个方法的实现都是直接调用mServiceManager,以addService举例
1 2 3 4 public void addService (String name, IBinder service, boolean allowIsolated, int dumpPriority) throws RemoteException { mServiceManager.addService(name, service, allowIsolated, dumpPriority); }
这与直接使用IServiceManager.Stub.asInterface(remote)得到IServiceManager并没有什么区别
IServiceManager 我们将重点转到IServiceManager上,我们在源码中搜索不到IServiceManager.java文件,因为实际上这个文件是通过aidl生成的
关于aidl我们到后面再详细分析,现在我们只需要知道它其实是辅助我们进行binder通信的一种工具,aidl文件会在编译过程中生成出与之对应的java文件
IServiceManager的aidl文件路径为frameworks/native/libs/binder/aidl/android/os/IServiceManager.aidl
我们来看一下它生成出的IServiceManager.Stub.asInterface方法
1 2 3 4 5 6 7 8 9 10 11 public static android.os.IServiceManager asInterface (android.os.IBinder obj) if ((obj == null )) { return null ; } android.os.IInterface iin = obj.queryLocalInterface(DESCRIPTOR); if (((iin != null ) && (iin instanceof android.os.IServiceManager))) { return ((android.os.IServiceManager) iin); } return new android.os.IServiceManager.Stub.Proxy(obj); }
这里我们传入的IBinder是BinderProxy,它的queryLocalInterface永远返回null,所以这里返回的是IServiceManager.Stub.Proxy对象,我们接着看之前调用的getService方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Override public android.os.IBinder getService (java.lang.String name) throws android.os.RemoteException android.os.Parcel _data = android.os.Parcel.obtain(); android.os.Parcel _reply = android.os.Parcel.obtain(); android.os.IBinder _result; try { _data.writeInterfaceToken(DESCRIPTOR); _data.writeString(name); boolean _status = mRemote.transact(Stub.TRANSACTION_getService, _data, _reply, 0 ); _reply.readException(); _result = _reply.readStrongBinder(); } finally { _reply.recycle(); _data.recycle(); } return _result; }
Parcel Parcel是一个存放读取数据的容器,它的基本功能和使用相信进阶Android开发应该都懂,我们在这里只介绍一些关键性函数的含义,其他就不多赘述了,有机会的话以后单独开一章分析它
函数
作用
obtain
获取一个新的Parcel对象
ipcData、data
数据区首地址
ipcDataSize、dataSize
数据大小
ipcObjects
偏移数组首地址
ipcObjectsCount
IPC对象数量
dataPosition
数据指针当前的位置
dataCapacity
数据区的总容量(始终 >= dataSize)
这里获取了两个Parcel,一个_data用来传递参数数据,一个_reply用来接收回应。接着,_data首先调用writeInterfaceToken方法,这里的token是客户端与服务端的一个协定,服务端会校验我们写入的这个token,然后按照顺序将参数依次写入到_data中(序列化),然后通过binder调用远程服务真正的方法,然后检查异常。
对于无返回值的方法来说,到这一步已经结束了,但我们这个方法是有返回值的,所以我们需要一个_result,从_reply中读取出数据(反序列化),赋给_result,然后返回出去
BinderProxy.transact 我们重点看transact这一部分,通过我们之前的分析,我们知道mRemote是一个BinderProxy类型的对象,我们来看他的transact方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public boolean transact (int code, Parcel data, Parcel reply, int flags) throws RemoteException Binder.checkParcel(this , code, data, "Unreasonably large binder buffer" ); ... ... ... ... try { final boolean result = transactNative(code, data, reply, flags); if (reply != null && !warnOnBlocking) { reply.addFlags(Parcel.FLAG_IS_REPLY_FROM_BLOCKING_ALLOWED_OBJECT); } return result; } finally { ... } }
我这里简化了一下代码,可以看到,首先就是对Parcel大小的检查
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static void checkParcel (IBinder obj, int code, Parcel parcel, String msg) if (CHECK_PARCEL_SIZE && parcel.dataSize() >= 800 *1024 ) { StringBuilder sb = new StringBuilder(); sb.append(msg); sb.append(": on " ); sb.append(obj); sb.append(" calling " ); sb.append(code); sb.append(" size " ); sb.append(parcel.dataSize()); sb.append(" (data: " ); parcel.setDataPosition(0 ); sb.append(parcel.readInt()); sb.append(", " ); sb.append(parcel.readInt()); sb.append(", " ); sb.append(parcel.readInt()); sb.append(")" ); Slog.wtfStack(TAG, sb.toString()); } }
Android默认设置了Parcel数据传输不能超过800k ,当然,各个厂商是可以随意改动这里的代码的,如果超过了的话,便会调用Slog.wtfStack打印日志,需要注意的是,在当前进程不是系统进程并且系统也不是工程版本的情况下,这个方法是会结束进程的,所以在应用开发的时候,我们需要注意跨进程数据传输的大小,避免因此引发crash
省去中间的一些log、回调,接下来便是调用transactNative方法,这是一个native方法,实现在frameworks/base/core/jni/android_util_Binder.cpp中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 static jboolean android_os_BinderProxy_transact (JNIEnv* env, jobject obj, jint code, jobject dataObj, jobject replyObj, jint flags) if (dataObj == NULL ) { jniThrowNullPointerException(env, NULL ); return JNI_FALSE; } Parcel* data = parcelForJavaObject(env, dataObj); if (data == NULL ) { return JNI_FALSE; } Parcel* reply = parcelForJavaObject(env, replyObj); if (reply == NULL && replyObj != NULL ) { return JNI_FALSE; } IBinder* target = getBPNativeData(env, obj)->mObject.get(); if (target == NULL ) { jniThrowException(env, "java/lang/IllegalStateException" , "Binder has been finalized!" ); return JNI_FALSE; } ... status_t err = target->transact(code, *data, reply, flags); ... if (err == NO_ERROR) { return JNI_TRUE; } else if (err == UNKNOWN_TRANSACTION) { return JNI_FALSE; } signalExceptionForError(env, obj, err, true , data->dataSize()); return JNI_FALSE; }
这里首先是获得native层对应的Parcel并执行判断,Parcel实际上功能是在native中实现的,java中的Parcel类使用mNativePtr成员变量保存了其对应native中的Parcel的指针
然后调用getBPNativeData函数获得BinderProxy在native中对应的BinderProxyNativeData,再通过里面的mObject域成员变量得到其对应的BpBinder,这个函数在之前分析javaObjectForIBinder的时候已经出现过了
BpBinder.transact 之后便是调用BpBinder的transact函数了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 status_t BpBinder::transact ( uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags) if (mAlive) { ... status_t status = IPCThreadState::self()->transact( mHandle, code, data, reply, flags); if (status == DEAD_OBJECT) mAlive = 0 ; return status; } return DEAD_OBJECT; }
这里有一个Alive判断,可以避免对一个已经死亡的binder服务再发起事务,浪费资源,除此之外便是调用IPCThreadState的transact函数了
IPCThreadState 路径:frameworks/native/libs/binder/IPCThreadState.cpp
还记得我们之前提到的ProcessState吗?IPCThreadState和它很像,ProcessState负责打开binder驱动并进行mmap映射,而IPCThreadState则是负责与binder驱动进行具体的交互
IPCThreadState也有一个self函数,与ProcessState的self不同的是,ProcessState是进程单例,而IPCThreadState是线程单例,我们来看看它是怎么实现的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 IPCThreadState* IPCThreadState::self () if (gHaveTLS.load(std ::memory_order_acquire)) { restart: const pthread_key_t k = gTLS; IPCThreadState* st = (IPCThreadState*)pthread_getspecific(k); if (st) return st; return new IPCThreadState; } if (gShutdown.load(std ::memory_order_relaxed)) { ALOGW("Calling IPCThreadState::self() during shutdown is dangerous, expect a crash.\n" ); return nullptr ; } pthread_mutex_lock(&gTLSMutex); if (!gHaveTLS.load(std ::memory_order_relaxed)) { int key_create_value = pthread_key_create(&gTLS, threadDestructor); if (key_create_value != 0 ) { pthread_mutex_unlock(&gTLSMutex); ALOGW("IPCThreadState::self() unable to create TLS key, expect a crash: %s\n" , strerror(key_create_value)); return nullptr ; } gHaveTLS.store(true , std ::memory_order_release); } pthread_mutex_unlock(&gTLSMutex); goto restart; }
gHaveTLS是一个原子类型的bool值,它在存取过程中需要指定内存序std::memory_order_xxx,在这里我们直接忽略掉,把它当成一个纯粹的bool值就好了
在这里,TLS的全称为Thread Local Storage,表示线程本地储存空间,和java中的ThreadLocal其实是一个作用
当一个线程初次获取IPCThreadState的时候,会先走到gHaveTLS为false的case,此时程序会创建一个key,作为存放线程本地变量的key,创建成功后将gHaveTLS置为true,然后goto到gHaveTLS为true的case,此时线程本地储存空间中暂时还是没有数据的,所以会new一个IPCThreadState出来,在IPCThreadState的构造函数中,会将自己保存到线程本地储存空间中,这样,当线程第二次再获取IPCThreadState的时候,便会直接走到pthread_getspecific这里获取并返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 IPCThreadState::IPCThreadState() : mProcess(ProcessState::self()), mServingStackPointer(nullptr ), mServingStackPointerGuard(nullptr ), mWorkSource(kUnsetWorkSource), mPropagateWorkSource(false ), mIsLooper(false ), mIsFlushing(false ), mStrictModePolicy(0 ), mLastTransactionBinderFlags(0 ), mCallRestriction(mProcess->mCallRestriction) { pthread_setspecific(gTLS, this ); clearCaller(); mIn.setDataCapacity(256 ); mOut.setDataCapacity(256 ); }
我们通过构造函数可以发现,它调用了pthread_setspecific函数将自身保存在了线程本地储存空间中
IPCThreadState中,成员变量mIn用于接收来自binder设备的数据,mOut用于储存发往binder设备的数据,他们的默认容量都为256字节
transact 我们接着看它的transact函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 status_t IPCThreadState::transact (int32_t handle, uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags) LOG_ALWAYS_FATAL_IF(data.isForRpc(), "Parcel constructed for RPC, but being used with binder." ); status_t err; flags |= TF_ACCEPT_FDS; ... err = writeTransactionData(BC_TRANSACTION, flags, handle, code, data, nullptr ); if (err != NO_ERROR) { if (reply) reply->setError(err); return (mLastError = err); } if ((flags & TF_ONE_WAY) == 0 ) { if (UNLIKELY(mCallRestriction != ProcessState::CallRestriction::NONE)) { if (mCallRestriction == ProcessState::CallRestriction::ERROR_IF_NOT_ONEWAY) { ALOGE("Process making non-oneway call (code: %u) but is restricted." , code); CallStack::logStack("non-oneway call" , CallStack::getCurrent(10 ).get(), ANDROID_LOG_ERROR); } else { LOG_ALWAYS_FATAL("Process may not make non-oneway calls (code: %u)." , code); } } if (reply) { err = waitForResponse(reply); } else { Parcel fakeReply; err = waitForResponse(&fakeReply); } ... } else { err = waitForResponse(nullptr , nullptr ); } return err; }
这个函数的重点在于writeTransactionData和waitForResponse,我们依次分析
writeTransactionData 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 status_t IPCThreadState::writeTransactionData (int32_t cmd, uint32_t binderFlags, int32_t handle, uint32_t code, const Parcel& data, status_t * statusBuffer) binder_transaction_data tr; tr.target.ptr = 0 ; tr.target.handle = handle; tr.code = code; tr.flags = binderFlags; tr.cookie = 0 ; tr.sender_pid = 0 ; tr.sender_euid = 0 ; const status_t err = data.errorCheck(); if (err == NO_ERROR) { tr.data_size = data.ipcDataSize(); tr.data.ptr.buffer = data.ipcData(); tr.offsets_size = data.ipcObjectsCount()*sizeof (binder_size_t ); tr.data.ptr.offsets = data.ipcObjects(); } else if (statusBuffer) { tr.flags |= TF_STATUS_CODE; *statusBuffer = err; tr.data_size = sizeof (status_t ); tr.data.ptr.buffer = reinterpret_cast <uintptr_t >(statusBuffer); tr.offsets_size = 0 ; tr.data.ptr.offsets = 0 ; } else { return (mLastError = err); } mOut.writeInt32(cmd); mOut.write(&tr, sizeof (tr)); return NO_ERROR; }
在分析这个函数之前,我们需要先回忆一下在前面binder驱动章节我们所学习的binder结构和通信过程:Android源码分析 - Binder驱动(中)
binder_tansaction首先会读取一个请求码cmd,当binder请求码为BC_TRANSACTION/BC_REPLY的时候,binder驱动所接收的参数为binder_transaction_data结构体,所以在这个函数中,我们将binder请求码(这里为BC_TRANSACTION)和binder_transaction_data结构体依次写入到mOut中,为之后binder_tansaction做准备
waitForResponse 数据准备好后,接着便来到了waitForResponse函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 status_t IPCThreadState::waitForResponse (Parcel *reply, status_t *acquireResult) uint32_t cmd; int32_t err; while (1 ) { if ((err=talkWithDriver()) < NO_ERROR) break ; err = mIn.errorCheck(); if (err < NO_ERROR) break ; if (mIn.dataAvail() == 0 ) continue ; cmd = (uint32_t )mIn.readInt32(); IF_LOG_COMMANDS() { alog << "Processing waitForResponse Command: " << getReturnString(cmd) << endl ; } switch (cmd) { case BR_ONEWAY_SPAM_SUSPECT: ... case BR_TRANSACTION_COMPLETE: if (!reply && !acquireResult) goto finish; break ; case BR_DEAD_REPLY: ... case BR_FAILED_REPLY: ... case BR_FROZEN_REPLY: ... case BR_ACQUIRE_RESULT: ... case BR_REPLY: { binder_transaction_data tr; err = mIn.read(&tr, sizeof (tr)); ALOG_ASSERT(err == NO_ERROR, "Not enough command data for brREPLY" ); if (err != NO_ERROR) goto finish; if (reply) { if ((tr.flags & TF_STATUS_CODE) == 0 ) { reply->ipcSetDataReference( reinterpret_cast <const uint8_t *>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast <const binder_size_t *>(tr.data.ptr.offsets), tr.offsets_size/sizeof (binder_size_t ), freeBuffer ); } else { err = *reinterpret_cast <const status_t *>(tr.data.ptr.buffer); freeBuffer(nullptr , reinterpret_cast <const uint8_t *>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast <const binder_size_t *>(tr.data.ptr.offsets), tr.offsets_size/sizeof (binder_size_t )); } } else { freeBuffer(nullptr , reinterpret_cast <const uint8_t *>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast <const binder_size_t *>(tr.data.ptr.offsets), tr.offsets_size/sizeof (binder_size_t )); continue ; } } goto finish; default : err = executeCommand(cmd); if (err != NO_ERROR) goto finish; break ; } } finish: if (err != NO_ERROR) { if (acquireResult) *acquireResult = err; if (reply) reply->setError(err); mLastError = err; logExtendedError(); } return err; }
这里有一个循环,正如函数名所描述,会一直等待到一整条binder事务链结束返回后才会退出这个循环,在这个循环的开头,便是talkWithDriver方法
talkWithDriver 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 status_t IPCThreadState::talkWithDriver (bool doReceive) if (mProcess->mDriverFD < 0 ) { return -EBADF; } binder_write_read bwr; const bool needRead = mIn.dataPosition() >= mIn.dataSize(); const size_t outAvail = (!doReceive || needRead) ? mOut.dataSize() : 0 ; bwr.write_size = outAvail; bwr.write_buffer = (uintptr_t )mOut.data(); if (doReceive && needRead) { bwr.read_size = mIn.dataCapacity(); bwr.read_buffer = (uintptr_t )mIn.data(); } else { bwr.read_size = 0 ; bwr.read_buffer = 0 ; } if ((bwr.write_size == 0 ) && (bwr.read_size == 0 )) return NO_ERROR; bwr.write_consumed = 0 ; bwr.read_consumed = 0 ; status_t err; do { if (ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0 ) err = NO_ERROR; else err = -errno; if (mProcess->mDriverFD < 0 ) { err = -EBADF; } } while (err == -EINTR); if (err >= NO_ERROR) { if (bwr.write_consumed > 0 ) { if (bwr.write_consumed < mOut.dataSize()) LOG_ALWAYS_FATAL("Driver did not consume write buffer. " "err: %s consumed: %zu of %zu" , statusToString(err).c_str(), (size_t )bwr.write_consumed, mOut.dataSize()); else { mOut.setDataSize(0 ); processPostWriteDerefs(); } } if (bwr.read_consumed > 0 ) { mIn.setDataSize(bwr.read_consumed); mIn.setDataPosition(0 ); } return NO_ERROR; } return err; }
这里的binder_write_read也是一个我们熟悉的结构,我们在之前的文章Android源码分析 - Binder驱动(中) 中了解过,关于binder通信的代码,我们需要结合着binder驱动一起看才能理解
在binder驱动层中,binder_ioctl_write_read函数会从用户空间读取一个binder_write_read结构,这个结构体主要描述了数据传输的大小和位置以及消费情况(已读/写数据大小),这么看来,talkWithDriver函数的结构就很清晰了:
创建出binder_write_read结构,根据之前的读取情况,决定是否读写数据,设置写数据内容和大小,设置读数据的空间和容量
调用binder驱动的ioctl
重置写缓存,根据ioctl的结果设置读缓存
这之后,waitForResponse函数就可以从读缓存mIn中读到数据了,我们回到这个函数中,发现它首先从读缓存中读取了一个binder响应码,然后根据这个响应码再处理接下来的工作
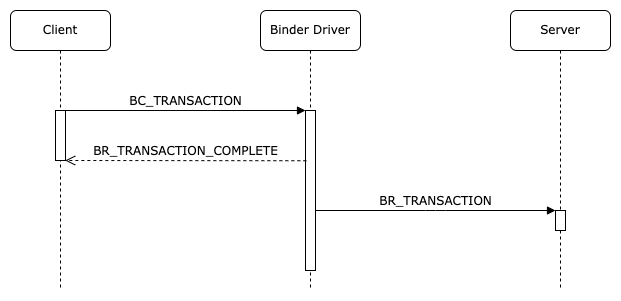
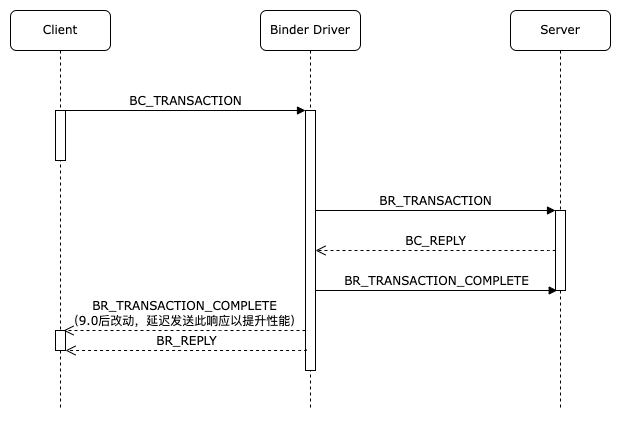
处理Reply 在此之前,我们先回顾一下一次binder_tansaction的整个过程,根据事务类型,分为两种情况:
我们先对照着看TF_ONE_WAY的情况
1 2 3 4 5 6 7 8 9 10 11 12 status_t IPCThreadState::waitForResponse (Parcel *reply, status_t *acquireResult) switch (cmd) { ... case BR_TRANSACTION_COMPLETE: if (!reply && !acquireResult) goto finish; break ; ... } } }
对于TF_ONE_WAY模式来说,客户端在收到BR_TRANSACTION_COMPLETE响应码后则返回,不会再等待BR_REPLY
而对于非TF_ONE_WAY模式来说,客户端不仅会收到BR_TRANSACTION_COMPLETE响应码,之后还会阻塞等待binder驱动给它发来BR_REPLY响应码,这之后一次binder_transaction才算完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 status_t IPCThreadState::waitForResponse (Parcel *reply, status_t *acquireResult) switch (cmd) { ... case BR_REPLY: { binder_transaction_data tr; err = mIn.read(&tr, sizeof (tr)); ALOG_ASSERT(err == NO_ERROR, "Not enough command data for brREPLY" ); if (err != NO_ERROR) goto finish; if (reply) { if ((tr.flags & TF_STATUS_CODE) == 0 ) { reply->ipcSetDataReference( reinterpret_cast <const uint8_t *>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast <const binder_size_t *>(tr.data.ptr.offsets), tr.offsets_size/sizeof (binder_size_t ), freeBuffer ); } else { err = *reinterpret_cast <const status_t *>(tr.data.ptr.buffer); freeBuffer(nullptr , reinterpret_cast <const uint8_t *>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast <const binder_size_t *>(tr.data.ptr.offsets), tr.offsets_size/sizeof (binder_size_t )); } } else { freeBuffer(nullptr , reinterpret_cast <const uint8_t *>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast <const binder_size_t *>(tr.data.ptr.offsets), tr.offsets_size/sizeof (binder_size_t )); continue ; } } goto finish; ... } } }
一般来说,非TF_ONE_WAY模式肯定是需要一个reply来接收的,即reply != null,此时我们来看看接收正常reply的过程(接收32位状态码没什么好说的,直接从读缓冲区中强制类型转换出一个32位的code就完事了)
这里我们就需要看一下Parcel的ipcSetDataReference函数了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void Parcel::ipcSetDataReference (const uint8_t * data, size_t dataSize, const binder_size_t * objects, size_t objectsCount, release_func relFunc) LOG_ALWAYS_FATAL_IF(relFunc == nullptr , "must provide cleanup function" ); freeData(); auto * kernelFields = maybeKernelFields(); LOG_ALWAYS_FATAL_IF(kernelFields == nullptr ); mData = const_cast <uint8_t *>(data); mDataSize = mDataCapacity = dataSize; kernelFields->mObjects = const_cast <binder_size_t *>(objects); kernelFields->mObjectsSize = kernelFields->mObjectsCapacity = objectsCount; mOwner = relFunc; binder_size_t minOffset = 0 ; for (size_t i = 0 ; i < kernelFields->mObjectsSize; i++) { binder_size_t offset = kernelFields->mObjects[i]; if (offset < minOffset) { ALOGE("%s: bad object offset %" PRIu64 " < %" PRIu64 "\n" , __func__, (uint64_t )offset, (uint64_t )minOffset); kernelFields->mObjectsSize = 0 ; break ; } const flat_binder_object* flat = reinterpret_cast <const flat_binder_object*>(mData + offset); uint32_t type = flat->hdr.type; if (!(type == BINDER_TYPE_BINDER || type == BINDER_TYPE_HANDLE || type == BINDER_TYPE_FD)) { ... kernelFields->mObjectsSize = 0 ; break ; } minOffset = offset + sizeof (flat_binder_object); } scanForFds(); }
其实这个函数也不复杂,我们知道binder_mmap做到了一次拷贝,将数据拷贝到了内核物理内存中,然后将其与用户空间虚拟内存做了映射,所以这个函数此时只需要将数据的地址,大小等等无脑赋值进去,客户端后续便可以用Parcel提供的函数方便的从中读取数据了
freeBuffer 最后我们再来看一下freeBuffer这个释放缓冲区的方法,
1 2 3 4 5 6 7 8 9 10 11 12 void IPCThreadState::freeBuffer (Parcel* parcel, const uint8_t * data, size_t , const binder_size_t * , size_t ) ... if (parcel != nullptr ) parcel->closeFileDescriptors(); IPCThreadState* state = self(); state->mOut.writeInt32(BC_FREE_BUFFER); state->mOut.writePointer((uintptr_t )data); state->flushIfNeeded(); }
可以看到,这里向binder驱动发送了一个BC_FREE_BUFFER请求,然后binder驱动会负责回收这块缓冲区内存
我们在Parcel::ipcSetDataReference函数中可以发现,它将freeBuffer函数指针赋值给了mOwner,等到什么时候不需要这个Parcel了,便会调用这个函数进行缓冲区内存回收
结束 到这里,我们客户端与binder驱动沟通交互的分析就结束了,相比binder驱动而言,framework层的binder就好理解多了,下一章我们会从服务端的角度来看,它是怎么从binder驱动接收并处理客户端的请求的